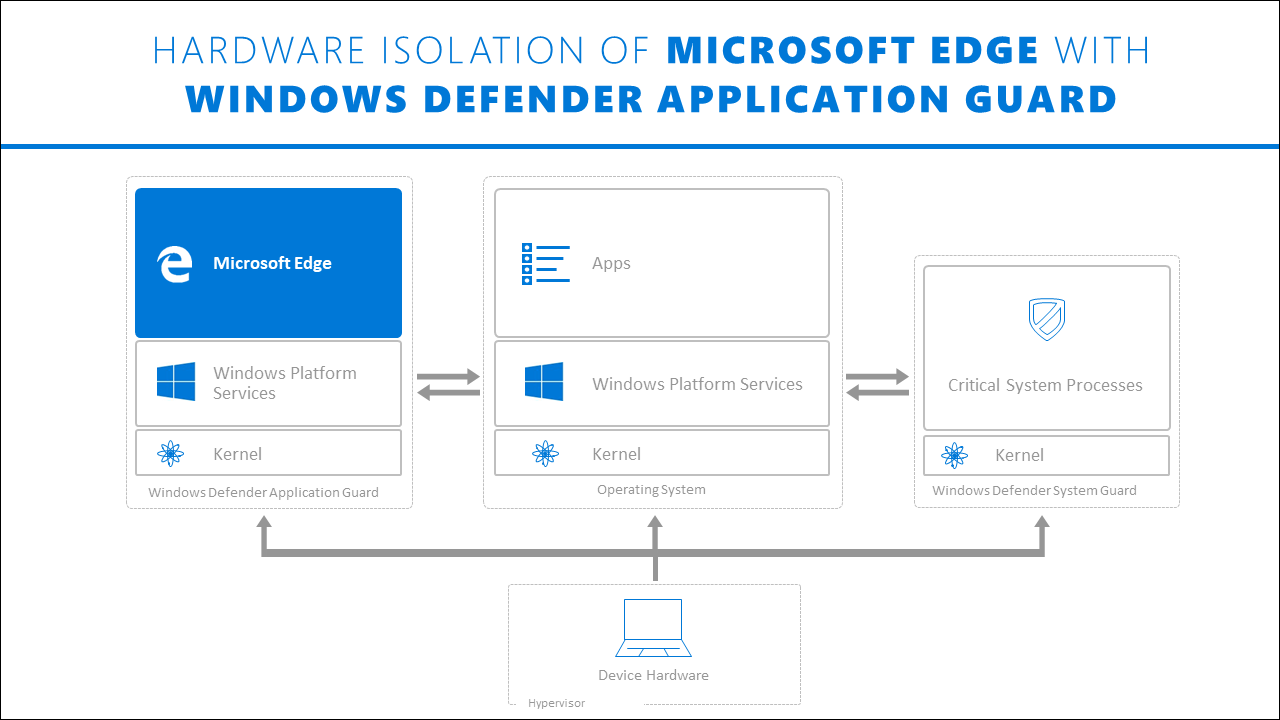
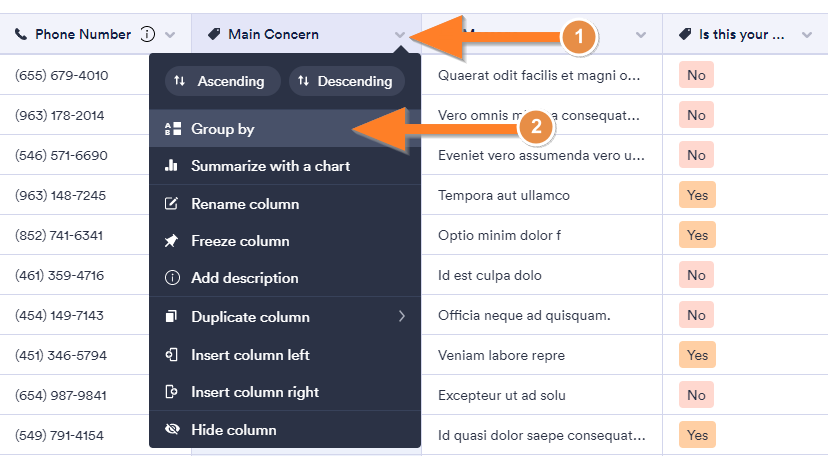
We can group the resultset in SQL on multiple column values. All the column values defined as grouping criteria should match with other records column values to group them to a single record. The group by clause is most often used along with the aggregate functions like MAX(), MIN(), COUNT(), SUM(), etc to get the summarized data from the table or multiple tables joined together. Grouping on multiple columns is most often used for generating queries for reports, dashboarding, etc.

Let us use the aggregate functions in the group by clause with multiple columns. This means given for the expert named Payal, two different records will be retrieved as there are two different values for session count in the table educba_learning that are 750 and 950. The presence of HAVING turns a query into a grouped query even if there is no GROUP BY clause.
This is the same as what happens when the query contains aggregate functions but no GROUP BY clause. All the selected rows are considered to form a single group, and the SELECT list and HAVING clause can only reference table columns from within aggregate functions. Such a query will emit a single row if the HAVING condition is true, zero rows if it is not true. The GROUP BY clause groups together rows in a table with non-distinct values for the expression in the GROUP BY clause. For multiple rows in the source table with non-distinct values for expression, theGROUP BY clause produces a single combined row. GROUP BY is commonly used when aggregate functions are present in the SELECT list, or to eliminate redundancy in the output.

How Do You Select Multiple Columns In Group By Clause Group by is done for clubbing together the records that have the same values for the criteria that are defined for grouping. When a single column is considered for grouping then the records containing the same value for that column on which criteria are defined are grouped into a single record for the resultset. Function_nameFunction calls can appear in the FROM clause. When the optional WITH ORDINALITY clause is added to the function call, a new column is appended after all the function's output columns with numbering for each row. This syntax allows users to perform analysis that requires aggregation on multiple sets of columns in a single query. Complex grouping operations do not support grouping on expressions composed of input columns.

Expressions specified in the SELECT clause are calculated after all the operations in the clauses described above are finished. These expressions work as if they apply to separate rows in the result. If expressions in the SELECT clause contain aggregate functions, then ClickHouse processes aggregate functions and expressions used as their arguments during the GROUP BY aggregation. The UNION operator computes the set union of the rows returned by the involved SELECT statements. A row is in the set union of two result sets if it appears in at least one of the result sets. The two SELECT statements that represent the direct operands of the UNION must produce the same number of columns, and corresponding columns must be of compatible data types.

Athena supports complex aggregations using GROUPING SETS, CUBE and ROLLUP. GROUP BY GROUPING SETS specifies multiple lists of columns to group on. GROUP BY CUBE generates all possible grouping sets for a given set of columns. GROUP BY ROLLUP generates all possible subtotals for a given set of columns. Matt contributed this handy SQL techniques to pivot one row of several columns into a single column with several row, using the Oracle Cross join syntax.
Matt notes that the Cross join "has other uses in conjunction with a WHERE clause to create triangular result sets for rolling totals etc ". GROUP BY will condense into a single row all selected rows that share the same values for the grouped expressions. An expression used inside a grouping_element can be an input column name, or the name or ordinal number of an output column , or an arbitrary expression formed from input-column values. In case of ambiguity, a GROUP BY name will be interpreted as an input-column name rather than an output column name. In Spark SQL, select() function is used to select one or multiple columns, nested columns, column by index, all columns, from the list, by regular expression from a DataFrame. Select() is a transformation function in Spark and returns a new DataFrame with the selected columns.

In general, UNBOUNDED PRECEDING means that the frame starts with the first row of the partition, and similarly UNBOUNDED FOLLOWING means that the frame ends with the last row of the partition . The value PRECEDING and value FOLLOWING cases are currently only allowed in ROWS mode. They indicate that the frame starts or ends with the row that many rows before or after the current row. Value must be an integer expression not containing any variables, aggregate functions, or window functions. The value must not be null or negative; but it can be zero, which selects the current row itself.

Aggregate functions, if any are used, are computed across all rows making up each group, producing a separate value for each group. When a FILTER clause is present, only those rows matching it are included in the input to that aggregate function. In the result set, the order of columns is the same as the order of their specification by the select expressions. If a select expression returns multiple columns, they are ordered the same way they were ordered in the source relation or row type expression. The ORDER BY clause specifies a column or expression as the sort criterion for the result set.
If an ORDER BY clause is not present, the order of the results of a query is not defined. Column aliases from a FROM clause or SELECT list are allowed. If a query contains aliases in the SELECT clause, those aliases override names in the corresponding FROM clause. A functional dependency exists if the grouped columns are the primary key of the table containing the ungrouped column.

You can select the single or multiple columns of the Spark DataFrame by passing the column names you wanted to select to the select() function. Since DataFrame is immutable, this creates a new DataFrame with a selected columns. In order to select column in pyspark we will be using select function.

Select() function is used to select single column and multiple columns in pyspark. We will explain how to select column in Pyspark using regular expression and also by column position with an example. In the SQL-92 standard, an ORDER BY clause can only use output column names or numbers, while a GROUP BY clause can only use expressions based on input column names.
If specific tables are named in a locking clause, then only rows coming from those tables are locked; any other tables used in the SELECT are simply read as usual. A locking clause without a table list affects all tables used in the statement. If a locking clause is applied to a view or sub-query, it affects all tables used in the view or sub-query. However, these clauses do not apply to WITH queries referenced by the primary query. If you want row locking to occur within a WITH query, specify a locking clause within the WITH query. Another difference is that these expressions can contain aggregate function calls, which are not allowed in a regular GROUP BY clause.

They are allowed here because windowing occurs after grouping and aggregation. Grouping_expressions allow you to perform complex grouping operations. You can use complex grouping operations to perform analysis that requires aggregation on multiple sets of columns in a single query. Corner cases exist where a distinct pivot_columns can end up with the same default column names. For example, an input column might contain both aNULL value and the string literal "NULL". When this happens, multiple pivot columns are created with the same name.

To avoid this situation, use aliases for pivot column names. SELECT AS STRUCT can be used in a scalar or array subquery to produce a single STRUCT type grouping multiple values together. Scalar and array subqueries are normally not allowed to return multiple columns, but can return a single column with STRUCT type. The GROUP BY clause is used in a SELECT statement to group rows into a set of summary rows by values of columns or expressions. It filters non-aggregated rows before the rows are grouped together.

To filter grouped rows based on aggregate values, use the HAVING clause. The HAVING clause takes any expression and evaluates it as a boolean, just like the WHERE clause. As with the select expression, if you reference non-grouped columns in the HAVINGclause, the behavior is undefined. Pandas comes with a whole host of sql-like aggregation functions you can apply when grouping on one or more columns. This is Python's closest equivalent to dplyr's group_by + summarise logic.

Here's a quick example of how to group on one or multiple columns and summarise data with aggregation functions using Pandas. First, you specify a column name or an expression on which to sort the result set of the query. If you specify multiple columns, the result set is sorted by the first column and then that sorted result set is sorted by the second column, and so on. All output expressions must be either aggregate functions or columns present in the GROUP BY clause. The INTERSECT operator returns rows that are found in the result sets of both the left and right input queries.

Unlike EXCEPT, the positioning of the input queries does not matter. Criteriacolumn1 , criteriacolumn2,…,criteriacolumnj – These are the columns that will be considered as the criteria to create the groups in the MYSQL query. There can be single or multiple column names on which the criteria need to be applied. SQL does not allow using the alias as the grouping criteria in the GROUP BY clause.

Note that multiple criteria of grouping should be mentioned in a comma-separated format. When you want to list down multiple columns for each entry but apply a single criterion applied to one column, you simply list down the columns to select then followed by the condition. For our example, we have added a table containing U.S. states' etymology on one sheet.

When you use a GROUP BY clause, you will get a single result row for each group of rows that have the same value for the expression given in GROUP BY. The key of it all is the way that we can use the "grouped rows" to actually re-expand those rows and use the average of the whole dataset against every single row. If you had, for example, another fridge, then the technique will still work – you wouldn't need to change anything from the query itself.

The INTERSECT operator computes the set intersection of the rows returned by the involved SELECT statements. A row is in the intersection of two result sets if it appears in both result sets. This left-hand row is extended to the full width of the joined table by inserting null values for the right-hand columns. Note that only the JOIN clause's own condition is considered while deciding which rows have matches. The FROM clause specifies one or more source tables for the SELECT. If multiple sources are specified, the result is the Cartesian product of all the sources.

But usually qualification conditions are added to restrict the returned rows to a small subset of the Cartesian product. The query returns only distinct values in the specified column. In other words, it removes the duplicate values in the column from the result set.
Use the OFFSET clause to discard a number of leading rows from the result set. If the ORDER BY clause is present, the OFFSET clause is evaluated over a sorted result set, and the set remains sorted after the skipped rows are discarded. If the query has no ORDER BY clause, it is arbitrary which rows are discarded. If the count specified by OFFSET equals or exceeds the size of the result set, the final result is empty.

When the clause contains multiple expressions, the result set is sorted according to the first expression. Then the second expression is applied to rows that have matching values from the first expression, and so on. Column_name [, ...] is an optional list of output column names. The number of column names must be equal to or less than the number of columns defined by subquery. The GROUP BY clause divides the rows returned from the SELECTstatement into groups. For each group, you can apply an aggregate function e.g.,SUM() to calculate the sum of items or COUNT()to get the number of items in the groups.

The UNION operator combines the result sets of two or more input queries by pairing columns from the result set of each query and vertically concatenating them. Set operators combine results from two or more input queries into a single result set. You must specify ALL or DISTINCT; if you specify ALL, then all rows are retained. The USING clause requires a column list of one or more columns which occur in both input tables. It performs an equality comparison on that column, and the rows meet the join condition if the equality comparison returns TRUE. Use the GROUP BY clause with aggregate functions in a SELECT statement to collect data across multiple records.

In this lesson you learned to use the SQL GROUP BY and aggregate functions to increase the power expressivity of the SQL SELECT statement. You know about the collapse issue, and understand you cannot reference individual records once the GROUP BY clause is used. We can observe that for the expert named Payal two records are fetched with session count as 1500 and 950 respectively. Note that the aggregate functions are used mostly for numeric valued columns when group by clause is used.

The GROUP BY clause is often used with aggregate functions such as AVG(), COUNT(), MAX(), MIN() and SUM(). In this case, the aggregate function returns the summary information per group. For example, given groups of products in several categories, the AVG() function returns the average price of products in each category.

You can use any of the grouping functions in your select expression. Their values will be calculated based on all the rows that have been grouped together for each result row. If you select a non-grouped column or a value computed from a non-grouped column, it is undefined which row the returned value is taken from. This is not permitted if the ONLY_FULL_GROUP_BY SQL_MODE is used. If you specify the GROUP BY clause, columns referenced must be all the columns in the SELECT clause that do not contain an aggregate function.

These columns can either be the column, an expression, or the ordinal number in the column list. If you want to break your output into smaller groups, if you specify multiple column names or expressions in the GROUP BY clause. Output in each group must satisfy a specific combination of the expressions listed in the GROUP BY clause.

The more columns or expressions entered in the GROUP BY clause, the smaller the groups will be. Note that this will result in locking all rows of mytable, whereas FOR UPDATE at the top level would lock only the actually returned rows. This can make for a significant performance difference, particularly if the ORDER BY is combined with LIMIT or other restrictions. So this technique is recommended only if concurrent updates of the ordering columns are expected and a strictly sorted result is required. The result of EXCEPT does not contain any duplicate rows unless the ALL option is specified. With ALL, a row that has m duplicates in the left table and n duplicates in the right table will appear max(m-n,0) times in the result set.